https://school.programmers.co.kr/learn/courses/30/lessons/42627
프로그래머스
코드 중심의 개발자 채용. 스택 기반의 포지션 매칭. 프로그래머스의 개발자 맞춤형 프로필을 등록하고, 나와 기술 궁합이 잘 맞는 기업들을 매칭 받으세요.
programmers.co.kr
문제 설명
하드디스크는 한 번에 하나의 작업만 수행할 수 있습니다. 디스크 컨트롤러를 구현하는 방법은 여러 가지가 있습니다. 가장 일반적인 방법은 요청이 들어온 순서대로 처리하는 것입니다.
예를들어
- 0ms 시점에 3ms가 소요되는 A작업 요청
- 1ms 시점에 9ms가 소요되는 B작업 요청
- 2ms 시점에 6ms가 소요되는 C작업 요청
와 같은 요청이 들어왔습니다. 이를 그림으로 표현하면 아래와 같습니다.
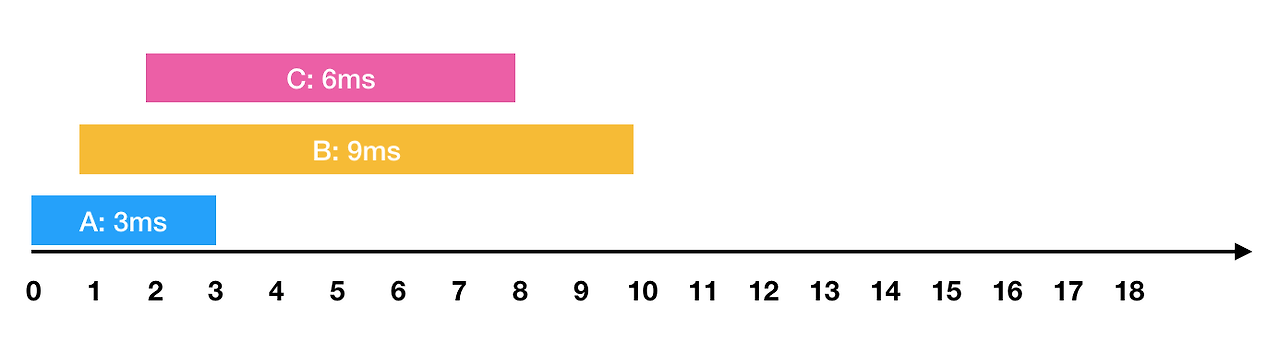
한 번에 하나의 요청만을 수행할 수 있기 때문에 각각의 작업을 요청받은 순서대로 처리하면 다음과 같이 처리 됩니다.

- A: 3ms 시점에 작업 완료 (요청에서 종료까지 : 3ms)
- B: 1ms부터 대기하다가, 3ms 시점에 작업을 시작해서 12ms 시점에 작업 완료(요청에서 종료까지 : 11ms)
- C: 2ms부터 대기하다가, 12ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 16ms)
이 때 각 작업의 요청부터 종료까지 걸린 시간의 평균은 10ms(= (3 + 11 + 16) / 3)가 됩니다.
하지만 A → C → B 순서대로 처리하면
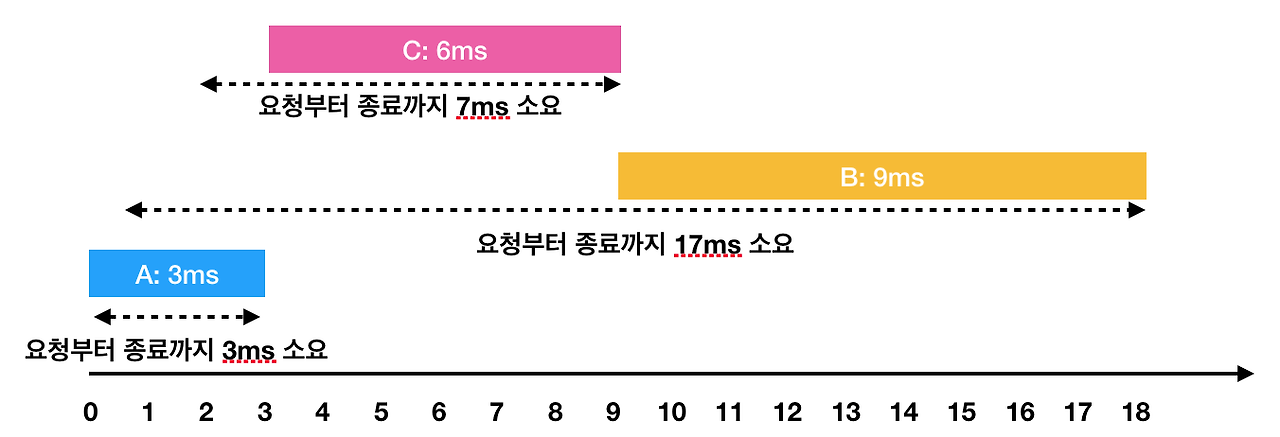
- A: 3ms 시점에 작업 완료(요청에서 종료까지 : 3ms)
- C: 2ms부터 대기하다가, 3ms 시점에 작업을 시작해서 9ms 시점에 작업 완료(요청에서 종료까지 : 7ms)
- B: 1ms부터 대기하다가, 9ms 시점에 작업을 시작해서 18ms 시점에 작업 완료(요청에서 종료까지 : 17ms)
이렇게 A → C → B의 순서로 처리하면 각 작업의 요청부터 종료까지 걸린 시간의 평균은 9ms(= (3 + 7 + 17) / 3)가 됩니다.
각 작업에 대해 [작업이 요청되는 시점, 작업의 소요시간]을 담은 2차원 배열 jobs가 매개변수로 주어질 때, 작업의 요청부터 종료까지 걸린 시간의 평균을 가장 줄이는 방법으로 처리하면 평균이 얼마가 되는지 return 하도록 solution 함수를 작성해주세요. (단, 소수점 이하의 수는 버립니다)
제한 사항- jobs의 길이는 1 이상 500 이하입니다.
- jobs의 각 행은 하나의 작업에 대한 [작업이 요청되는 시점, 작업의 소요시간] 입니다.
- 각 작업에 대해 작업이 요청되는 시간은 0 이상 1,000 이하입니다.
- 각 작업에 대해 작업의 소요시간은 1 이상 1,000 이하입니다.
- 하드디스크가 작업을 수행하고 있지 않을 때에는 먼저 요청이 들어온 작업부터 처리합니다.
문제에 주어진 예와 같습니다.
- 0ms 시점에 3ms 걸리는 작업 요청이 들어옵니다.
- 1ms 시점에 9ms 걸리는 작업 요청이 들어옵니다.
- 2ms 시점에 6ms 걸리는 작업 요청이 들어옵니다.
import java.util.*;
class Solution {
public int solution(int[][] jobs) {
Arrays.sort(jobs, (a, b) -> a[0] - b[0]);
Queue<int[]> pq = new PriorityQueue<>((a, b) -> a[1] - b[1]);
int entime = 0;
int now = 0;
int time = 0;
while(now < jobs.length || !pq.isEmpty()) {
while(now < jobs.length && jobs[now][0] <= time) {
pq.add(jobs[now++]);
}
if(pq.isEmpty()) {
time = jobs[now][0];
} else {
int[] job = pq.poll();
time += job[1];
entime += time - job[0];
}
}
return entime / jobs.length;
}
}기본적으로 매개변수로 받은 2차원 배열 jobs도 정렬이 필요했고 우선순위 큐 pd도 특정 인덱스 값을 사용한 정렬이 역시 필요했다. 우선 jobs 배열을 Arrays.sort와 람다식을 사용하여 정렬해주었다. (a, b) -> a[0] - b0]) 을 매개변수로 주었는데 이 뜻은 각 배열 a,b 의 [0]번째 인덱스인 요청 시각을 기준으로 비교하여 오름차순 정렬해주는 것이다. 오름차순 정렬을 해준 이유는 우선 SJF를 사용하여 요청 시각이 가장 먼저인 task를 먼저 처리하기 위해서였다. 다음은 pq 정렬인데 a[1] 즉, task의 실행시간이 빠른 기준으로 정렬해주도록 구현하였다.
먼저 누적된 시간을 저장하기 위한 entime, 현재 인덱스 뜻하는 now, 현재 시간을 뜻하는 time을 0으로 초기화해 주었다. 그 뒤, while문을 사용하여 모든 태스크를 뜻하는 jobs.length 가 현재 인덱스와 비교하여 아직 큐 추가되지 않은 작업이 있는지 확인하고 우선순위 큐 pq가 비어있지 않을 경우를 조건으로 주어 큐에 이미 들어온 처리해야할 작업이 남아 있는지 확인하여 모든 task들이 처리하도록 하였다. 다음으로 jobs의 now에 해당하는 값을 현재 인덱스가jobs.length 보다 작고 해당 인덱스의 실행시간이 time보다 작거나 같다면 즉, 현재 시간 이하로 요청된 작업이라면(실행가능) pq 에 해당 jobs배열의 값을 pq에 add해주고 now를 1증가시켜주었다. if문은 pq가 비어있다면 아직 처리할 작업이 없다는 의미 이므로 시간을 다음 작업의 요청시간으로 즉, 시간이 진행되어 다음 작업처리가 가능하도록 해주었다. 그렇게 시간을 진행 시키다가 처리가능한 작업이 pq에 추가되었을 때 else문이 실행되고 해당 job을 poll을 사용하여 우선순위 상 가장 빠른(실행 시간이) task를 꺼내오고 해당 작업의 실행에 소요된 시간만큼 time을 증가시켜 주었다. 그 뒤, 완료된 작업에서 해당 작업의 요청시간을 빼준 값인 각 작업의 총 소요시간을 계산하여 누적시켜 주었다. 마지막으로 모든작업을 처리한 후에는 총 처리에 걸린 시간을 작업의 수로 나누어 평균을 구해 구현할 수 있었다.